한국어 NLP 대표 벤치마크 데이터셋
8개 종류의 주요 한국어 NLP Task에 대해 국내 주요 연구기관들이 참여한 한국어 NLP 대표 벤치마크 데이터셋

한국어 고유의 특성을 고려한 연구

일관된 고품질 데이터를 만들 수 있는 관리 능력

업스테이지 / 박성준 연구원 KLUE 프로젝트 총괄
셀렉트스타와 KLUE 데이터셋을 구축하며 가장 인상적이었던 부분은 데이터 품질 관리였습니다.셀렉트스타 담당자 분들의 역량과 열정덕분에 대표 한국어 NLP 벤치마크 데이터셋인 KLUE가 무사히 세상에 나올 수 있었다고 생각합니다. 상당히 어려운 난이도와 촉박한 일정이었음에도 불구하고 일관된 데이터 작업이 가능하도록 가이드라인이 수립되었고, 고품질 데이터를 만들 수 있는 작업자 선발과 교육, 전수 검사가 이뤄졌습니다.
데이터셋 스펙
TC
210,000 분류 태그 (70,000 개의 헤드라인 * 3 종의 분류)
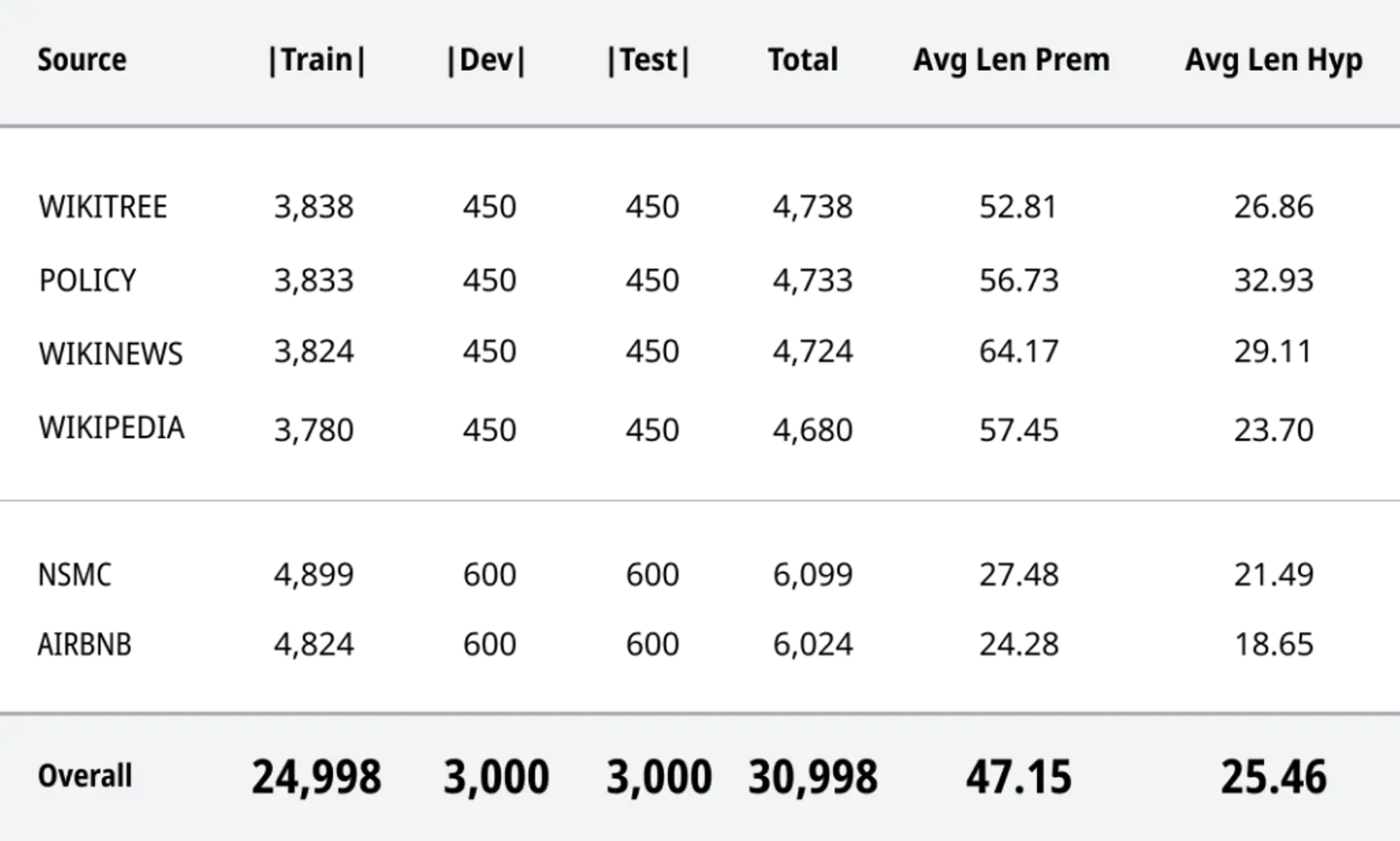
STS
NLI
MRC
- 뉴스 헤드라인 분류(Topic Classification, TC)
- 문장 유사도 비교(Semantic Textual Similarity, STS)
- 자연어 추론(Natural Language Inference, NLI)
- 기계 독해 이해(Machine Reading Comprehension, MRC)
셀렉트스타의 크라우드소싱 플랫폼 <캐시미션>을 통해 수많은 크라우드 워커들이 정확하고 신속하게 데이터를 수집하고 가공해 주었습니다. 이 4가지 항목이 정확히 어떤 것들인지, 그리고 셀렉트스타가 어떻게 수집하고 가공하였는지 알아보겠습니다.
뉴스 헤드라인 분류(Topic Classification, TC)
문장 유사도 비교(Semantic Textual Similarity, STS)
자연어 추론(Natural Language Inference, NLI)

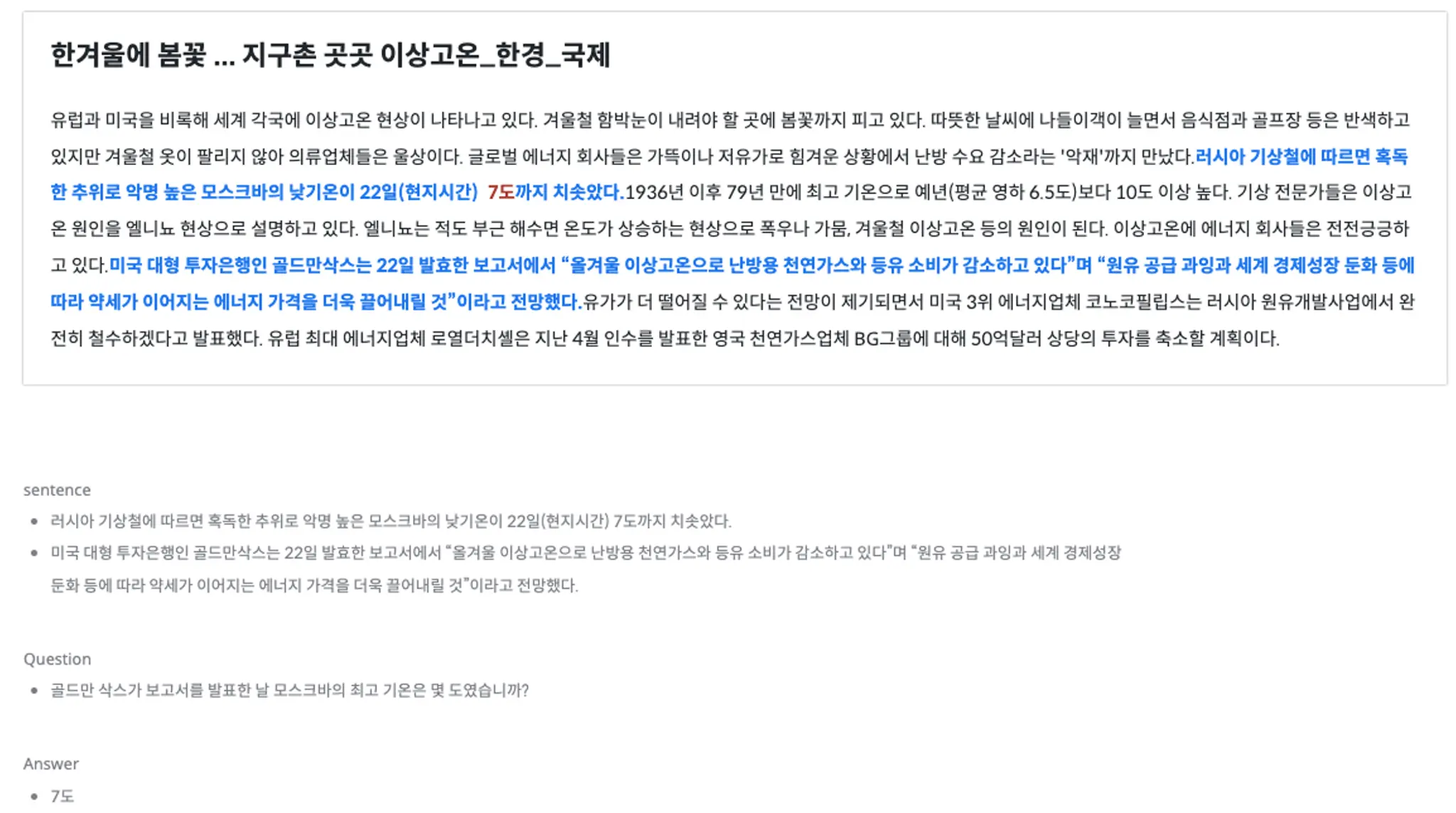
| Statistics | SNLI | MNLI | KLUE-NLI |
| Unanumious Gold Label | 58.30% | 58.20% | 76.29% |
| Individual Label = Gold Label | 89.00% | 88.70% | 92.63% |
Individual Label = Author’s Label | 85.80% | 85.20% | 90.92% |
| Gold Label = Author’s Label | 91.20% | 92.60% | 96.76% |
| Gold Label ≠ Author’s Label | 6.80% | 5.60% | 2.71% |
| No Gold Label(No 3 Labels Match) | 2.00% | 1.80% | 0.53% |
Author’s Label: 문장을 만든 작업자의 의도 / Gold Label: 작업자 5명 중 3명 이상이 같은 답_출처: KLUE 논문
기계 독해 이해(Machine Reading Comprehension, MRC)
프로젝트 진행 소감
김동연 | 데이터 사업팀, 프로젝트 매니저
1. Paraphrasing
2. Multi-sentence
3. Non-answerable
Paraphrasing에서는 허용 범위를 정량적으로 정하는 것이 어려웠고, Multi-sentence에서는 답변이 여러 개가 될 수 있는 사항을 피할 수 있게 문장을 조합하는 과정이 어려웠습니다. 대상 지문 또한 번역체, 또는 전문지식을 필요로한 글들이 있어 작업에 어려움이 있었지만 고객사와 지속적인 가이드 논의를 통해 작업의 일관성과 품질을 유지할 수 있는 방안을 마련할 수 있었습니다.
Open Datasets for Data-centric AI
위 데이터셋은 셀렉트스타 ‘OPEN DATASETS’에서 다운받으실 수 있습니다.