AI의 생명을 불어넣어주는 ‘학습데이터’. 셀렉트스타 김세엽 대표가 들려주는 인공지능 학습데이터 이야기입니다.
세엽님의 강의를 축약한 것으로 ‘여기  ’에서 전체 강의를 들을 수 있습니다
’에서 전체 강의를 들을 수 있습니다 

음성인식용 데이터셋의 경우
학습 데이터에 적거나 없었던 신조어, 유행어 등에 맞춰 데이터 최신화

1,100여 명의 크라우드 소싱 및 오프라인 참여로 다양한 데이터 수집
예시 - 마스크 착용 얼굴 데이터셋 구축

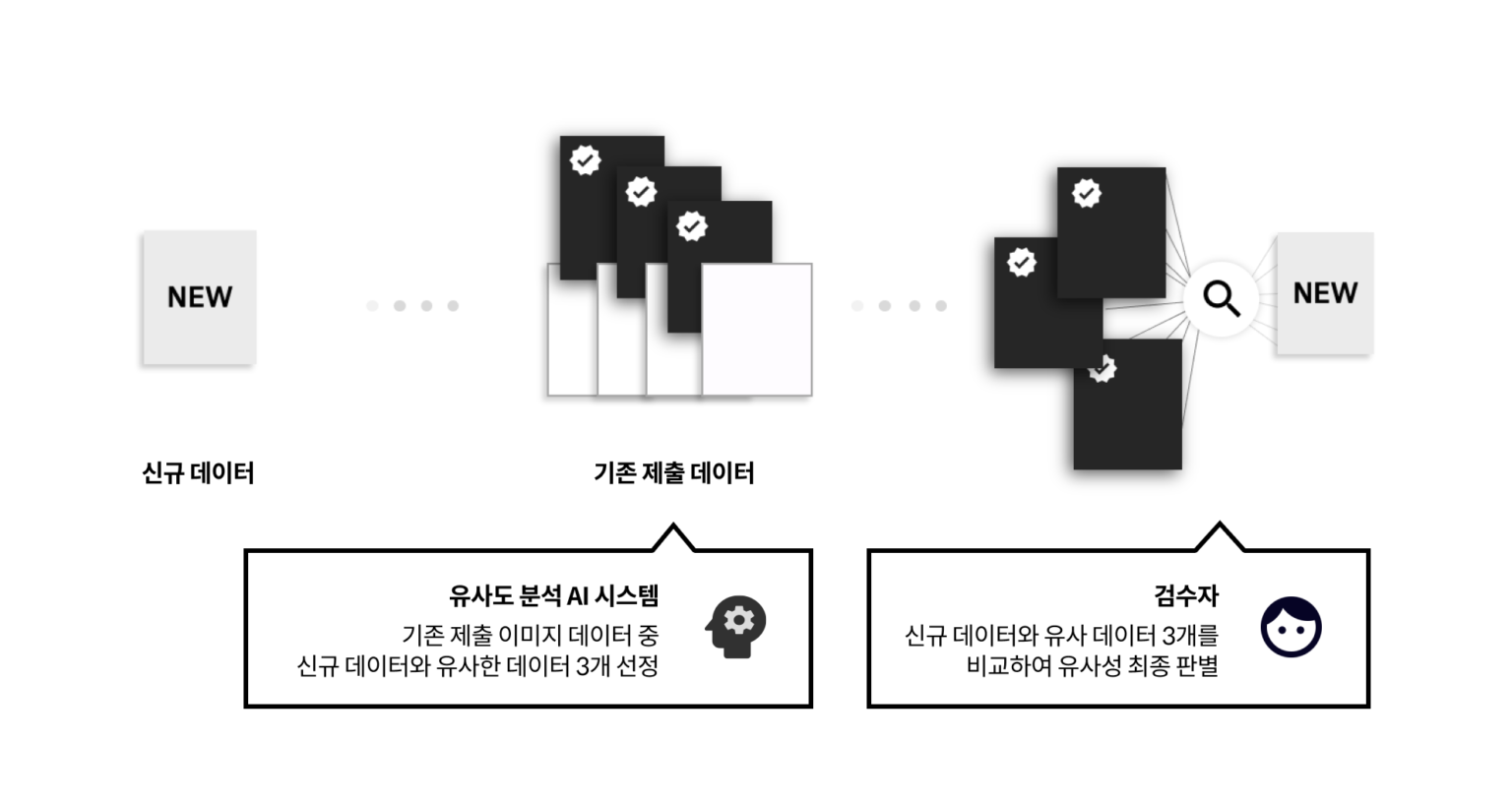
딥러닝 기술을 통한 유사 데이터 수집 필터링
국내외 주요 데이터 플랫폼 중 유일하게 적용