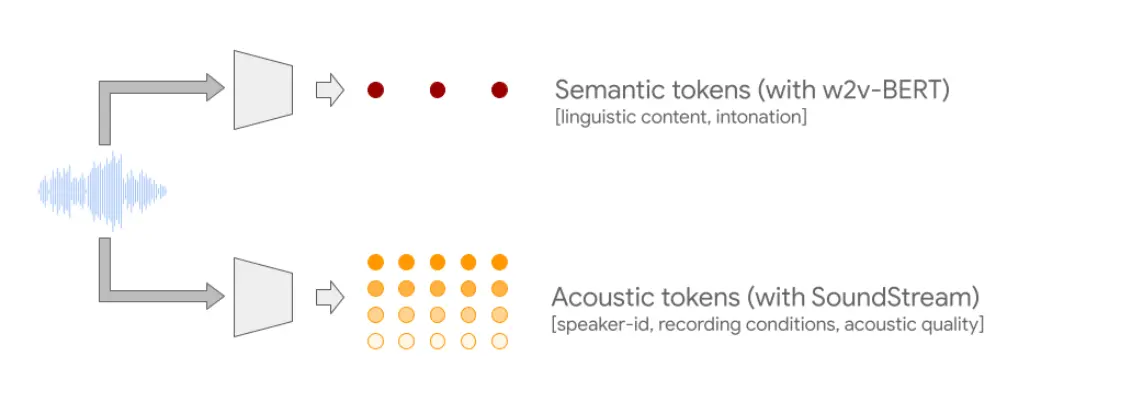
Wordcraft의 목표는 3가지입니다. Planning, Writing 그리고 Editing. Planning은 스토리의 전체적인 맥락을 기획하는 작업이고 Writing은 말 그대로 표현을 생성해내는 작업입니다. Editing은 이미 쓴 글을 다른 표현으로 고쳐쓰는 작업을 뜻합니다. 이를 위해 Wordcraft는 Continuation, Infilling, Elaboration, Rewriting 기능을 지원합니다.
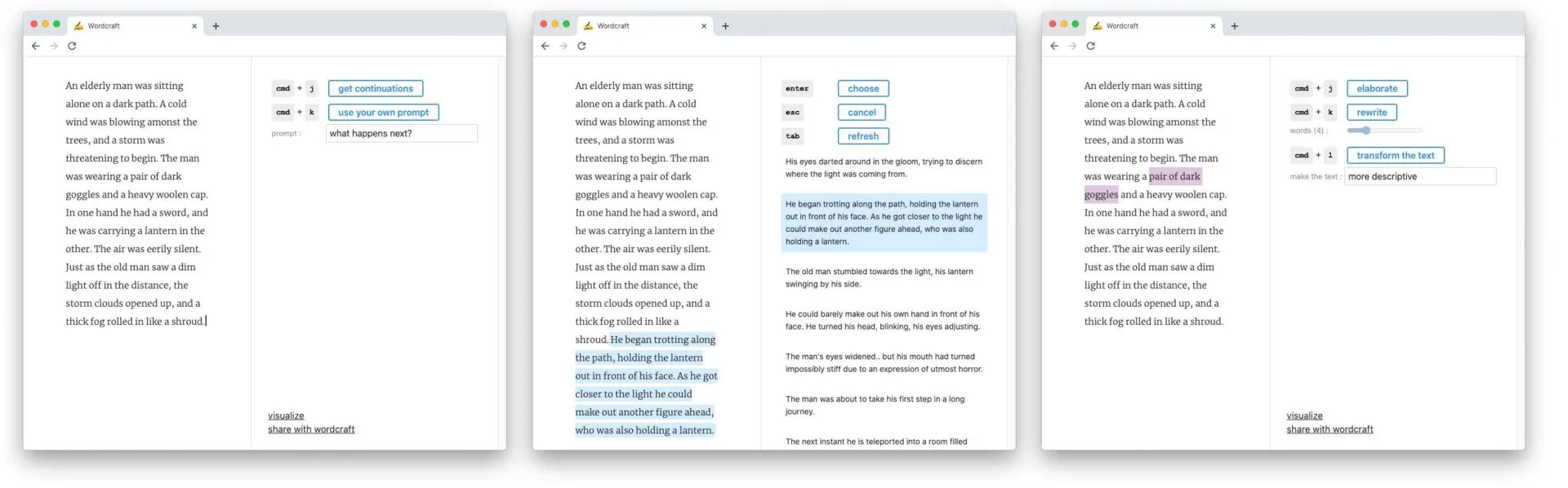
아래는 논문에서 소개된 Elaboration의 사례입니다.
Here’s my story so far: {The long shadow of the tree crept up the sidewalk.}
Describe the tree
‘나무의 긴 그림자가 드리운 거리’라는 스토리에 알맞은 나무를 묘사해달라고 요청했습니다. Wordcraft는 어떤 문장을 만들어냈을까요?
An old oak tree on the main street of a small town, the branches spread as large as the sky
‘작은 도시의 거리에 있는 오래된 참나무, 가지는 하늘만큼 넓게 뻗어 있다’라는 문학적인 표현을 생성해냈습니다! 이런 요청을 Freeform Prompt라고 하는데요, 알맞은 프롬프트를 작성하는 일이 어려울 수 있기에 Wordcraft는 좋은 프롬프트를 요청하기 위한 챗봇 기능을 제공합니다.
물론 아직 Wordcraft 만으로 일관적인 스토리를 만들어 내는 데는 한계가 있습니다. Wordcraft는 캐릭터의 관점이 바뀐다든가, 글쓰기 스타일을 유지하는 데 어려움을 보입니다. 하지만 디테일과 정교함 측면에서 탁월한 결과물을 보여주고 있어, 인간의 창작 활동을 돕는 툴로서 유용할 수 있습니다. 구글은 13명의 전문 작가가 Wordcraft를 활용하여 쓴 글들을 위 Wordcraft Writers Workshop에서 공개했습니다. 작가들은 Wordcraft가 실제로 창작의 영감을 받는 데 도움이 되었다고 말했습니다.